HowTo
Tipps und Tricks
Starte einen Ad-Hoc Batch per Webservice
Zielsetztung: einzelne / mehrere Actions / Sheets / Folder direkt ausführen ohne Verwendung der datasqill GUI
Angenommen es soll das Sheet mit der ID 45 und die Action mit der ID 73 ausgeführt werden. Dazu legt man folgende Datei run.json an:
{
"command":"RunElements",
"variableList":[{"variableName":"environment", "variableType":"String", "variableValue":"DEV"}],
"payload":{
"batchExecution":{
"batchName":"Test run",
"user":"ich",
"elementList":[
{
"elementType":"S",
"elementId":47
},
{
"elementType":"A",
"elementId":73
}
]
}
}
}
Auf dem datasqill Host führt man folgenden Befahl aus:
curl -d @run.json -H "Content-Type:application/json" http://localhost:17491/datasqill-server/service
wobei man den Port 17491 gegebenfalls ändern muss. Als Antwort erhält man ein Json mit der batchInstanceId. Diese kann man nun monitoren, um zu sehen, wann der Batch beendet ist (bzw. auf Fehler gelaufen ist):
{"requestId":4297280,"payload":{"batchInstanceId":4812038}}
Die Sektion vaiableList ist optional. In diesem Beispiel wird die Variable environment auf den Wert "DEV" gesetzt. Sie kann in den Transformationen verwendet werden.
Alternatives Script zum Starten einen Ad-Hoc Batch per Webservice sowie auf das Ablaufende warten
Alternativ zu curl kann man auch den Webclient verwenden der in datasqill benutzt wird. Dieses hat den Vorteil, dass dieser die Authentifizierungsmethoden benutzt, die man in datasqill einschalten kann.
Hier ein kleines Programm (unter Verwendung von jq) zum Starten eines Elements (RunElements), zum Warten auf einen Batch (WaitForStatus) und der Kombination von beidem (runAndWait):
runService.sh
#!/usr/bin/env bash
# $1 = command
# $2 = payload
call_service() {
local request='{"command":"'$1'", "payload":'$2'}'
java -cp ~datasqill/lib/datasqill-api.jar de.datasqill.util.CallDatasqillService http://localhost:17491/datasqill-server/service "$request"
}
do_work() {
local command=$1
case "$command" in
WaitForStatus)
# $2 = entityId
# $3 = status
# $4 = timeoutInSeconds
if [ "$3" == "" ]
then
local status=F
else
local status=$3
fi
if [ "$4" == "" ]
then
local timeoutInSeconds=null
else
local timeoutInSeconds=$4
fi
local payload='{"entityType":"I", "entityId":'$2', "status":"'$status'", "timeoutInSeconds":'$timeoutInSeconds'}'
;;
RunElements)
# $2 = elementType
# $3 = elementId
local payload='{"batchExecution":{"batchName":"Test Batch", "user":"TestUser", "elementList":[{"elementType":"'$2'", "elementId":'$3'}], "validate":false, "estimateDuration":false}}'
;;
runAndWait)
# $2 = elementType
# $3 = elementId
# $4 = timeoutInSeconds
local timeoutInSeconds=$4
if [ "$timeoutInSeconds" == "" ]
then
timeoutInSeconds="null"
fi
local result=`do_work RunElements "$2" "$3"`
local errorCode=`echo "$result" | jq -r '.error.errorCode'`
if [ "$errorCode" != "null" ]
then
echo "Error starting element: $result" >&2
return
fi
local instanceId=`echo "$result" | jq -r '.payload.batchInstanceId'`
if [ "$instanceId" == "null" ]
then
echo "Error reading batch instance id: $result" >&2
return
fi
# Loop over timeouts
while true
do
result=`do_work WaitForStatus $instanceId F $timeoutInSeconds`
#echo "result=$result"
local datasqillErrorID=`echo "$result" | jq -r '.datasqillError.datasqillErrorID'`
if [ "$datasqillErrorID" != "ERR_TIMEOUT_DURING_CHANGE_WAIT" ]
then
local errorCode=`echo "$result" | jq -r '.error.errorCode'`
if [ "$errorCode" != "null" ]
then
echo "Error while waiting for batch instance: $result" >&2
return
fi
local keys=`echo $result | jq -r 'keys[]'`
if [ "$keys" != "requestId" ]
then
echo "Unexpected result after wait: $result" >&2
fi
return
fi
done
;;
*)
local payload=null
;;
esac
call_service "$command" "$payload"
}
do_work $*
Möchte man den Batch mit der batchId 1234 starten und auf das Ende warten, dann sieht der Befehl folgendermaßen aus:
runService.sh runAndWait B 1234 120
Jetzt wird der Batch gestartet und es wird auf das erfolgreiche Ende gewartet (Status = "F").
Alle 120 Sekunden wird ein Timeout gemeldet, aber das shell script ruft den Service dann erneut auf. Dieses ist sinnvoll, falls die http-Verbindung bei langen Runs durch interne Einschränkungen (z.B. Serverseitig, Proxy) gekappt wird. Durch die manuell eingesstellte Timeout Zeit kann man das Timeout vom datasqill Service erzwingen und auf die entsprechende Fehlermeldung von datasqill reagieren (ERR_TIMEOUT_DURING_CHANGE_WAIT). Sollte es keine Abbrüche geben, kann man auch timeoutInSeconds weglassen und es wird unendlich lange gewartet. Setzt man timeoutInSeconds auf 0, dann wird genau einmal geprüft, ob die Wartebedingung erfüllt ist.
Das vorstehende bash script lässt sich natürlich auch für weitere Serviceaufrufe erweitern.
Zeitumstellung und nächtliche Batches
Es kann erforderlich sein, nächtliche Batches während der Zeitumstellung zu deaktivieren. Diesen Vorgang kann man mit datasqill mit diesen Schritten automatisieren:
- Eine neue Funktion is_dst_change_today im H2 Repository anlegen.
- Eine Verbindung zum datasqill Repository in datasqill anlegen.
- Die Zugangsdaten für diese Verbindung im Keyfile hinterlegen.
- Ein Sheet "Reschedule" und darin eine Action mit Quelle und Ziel anlegen und alles befüllen.
- Einen neuen Batch "Reschedule" anlegen, der jeden Tag einmal läuft.
is_dst_change_tonight
Zunächst einmal wird mit Hilfe von Java eine Funktion is_dst_change_tonight in der H2 definiert. Diese Funktion ermittelt, ob in der kommenden Nacht eine Zeitumstellung stattfindet:
CREATE ALIAS IF NOT EXISTS is_dst_change_tonight AS $$
boolean isDstChangeTonight() {
java.time.ZoneId zone = java.time.ZoneId.of("Europe/Berlin");
java.time.ZonedDateTime now = java.time.ZonedDateTime.now(zone);
java.time.ZonedDateTime nightEnd = now.plusDays(1).withHour(6).withMinute(0).withSecond(0).withNano(0);
java.time.zone.ZoneRules rules = zone.getRules();
java.time.Instant nowInstant = now.toInstant();
java.time.zone.ZoneOffsetTransition nextTransition = rules.nextTransition(nowInstant);
if (nextTransition != null) {
java.time.ZonedDateTime transitionTime = nextTransition.getDateTimeBefore().atZone(zone);
return !transitionTime.isBefore(now) && !transitionTime.isAfter(nightEnd);
}
return false;
}
$$;
Verbindung anlegen
Danach wird in datasqill eine Verbindung zum datasqill Repository angelegt. Die Verbindungen findet man unter Connections, links im Baum unter Settings:
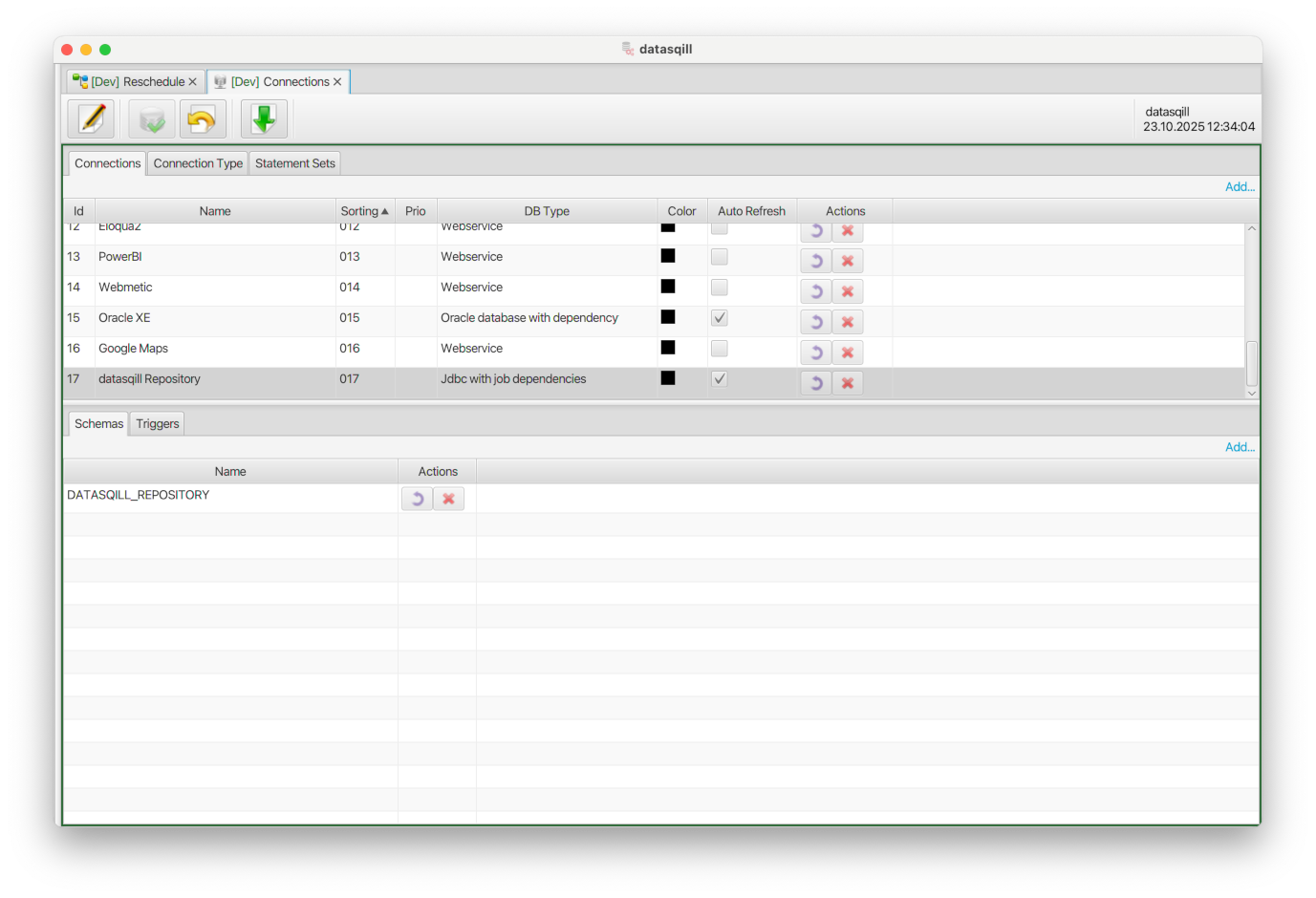
Mit Add werden eine neue Verbindung "datasqill Repository" und ein Schema "DATASQILL_REPOSITORY" hinzugefügt.
Zugangsdaten hinterlegen
Für die neue Verbindung müssen Zugangsdaten im Keyfile hinterlegt werden. Am einfachsten lässt sich das erreichen, indem man den vorhandenen Eintrag SQTS_DB_0 kopiert und daraus den für die neue Verbindungsnummer macht.
Sheet ud Action mit Quelle und Ziel anlegen
Auf einem neuen Sheet werden dann eine Action mit Quelle und Ziel angelegt:
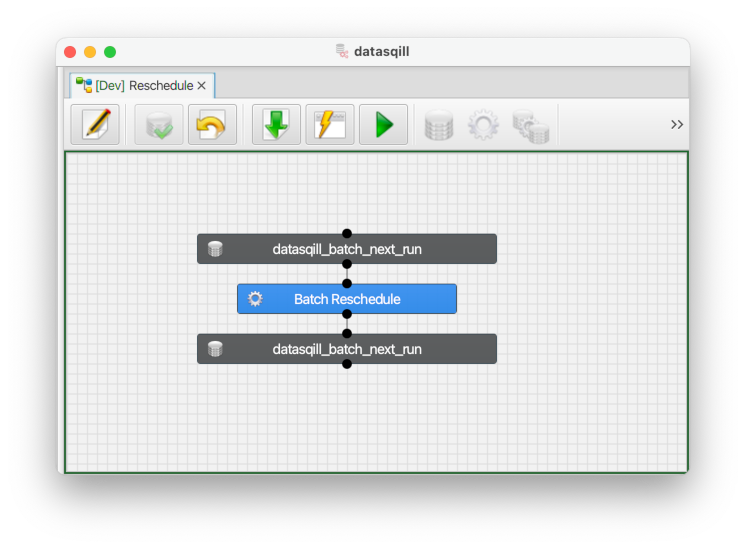
Die Objekte für Quelle und Ziel ist
- Typ: Table or View
- Verbindung: datasqill Repository
- Schema: DATASQILL_REPOSITORY
- Tabelle: datasqill_batch_next_run
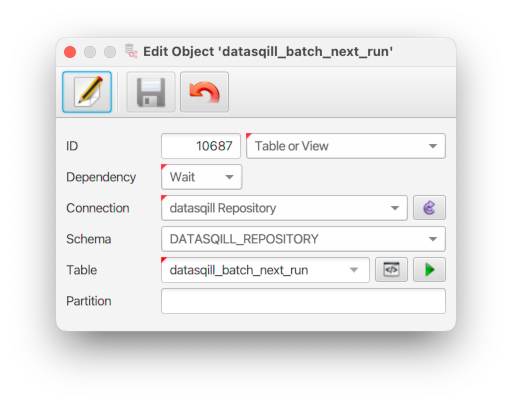
Die Action bekommt einen Namen, den Typ Upsert und als SQL diese Query:
SELECT batch_id
, start_dt + interval '1' DAY AS start_dt
FROM datasqill_batch_next_run
WHERE batch_id IN (6790)
AND is_dst_change_tonight()
AND start_dt <= CURRENT_TIMESTAMP + interval '14' hour
Damit setzt die Action das Startdatum für die Batches um einen Tag weiter, die in der Liste (IN-Klausel) enthalten sind. Im Beispiel ist dies der Batch mit der Id 6790.
Weiterhin wird die Bedingung geprüft, dass in der nächsten Nacht tatsächlich eine Zeitumstellung stattfindet.
Und schließlich werden nur Batches berücksichtigt, die innerhalb der nächsten 14 Stunden laufen. Das sorgt dafür, dass bei einer mehrfache Ausführung dieser Action die geplante Ausführungszeit nur einmal verschoben wird.
Batch "Reschedule" anlegen
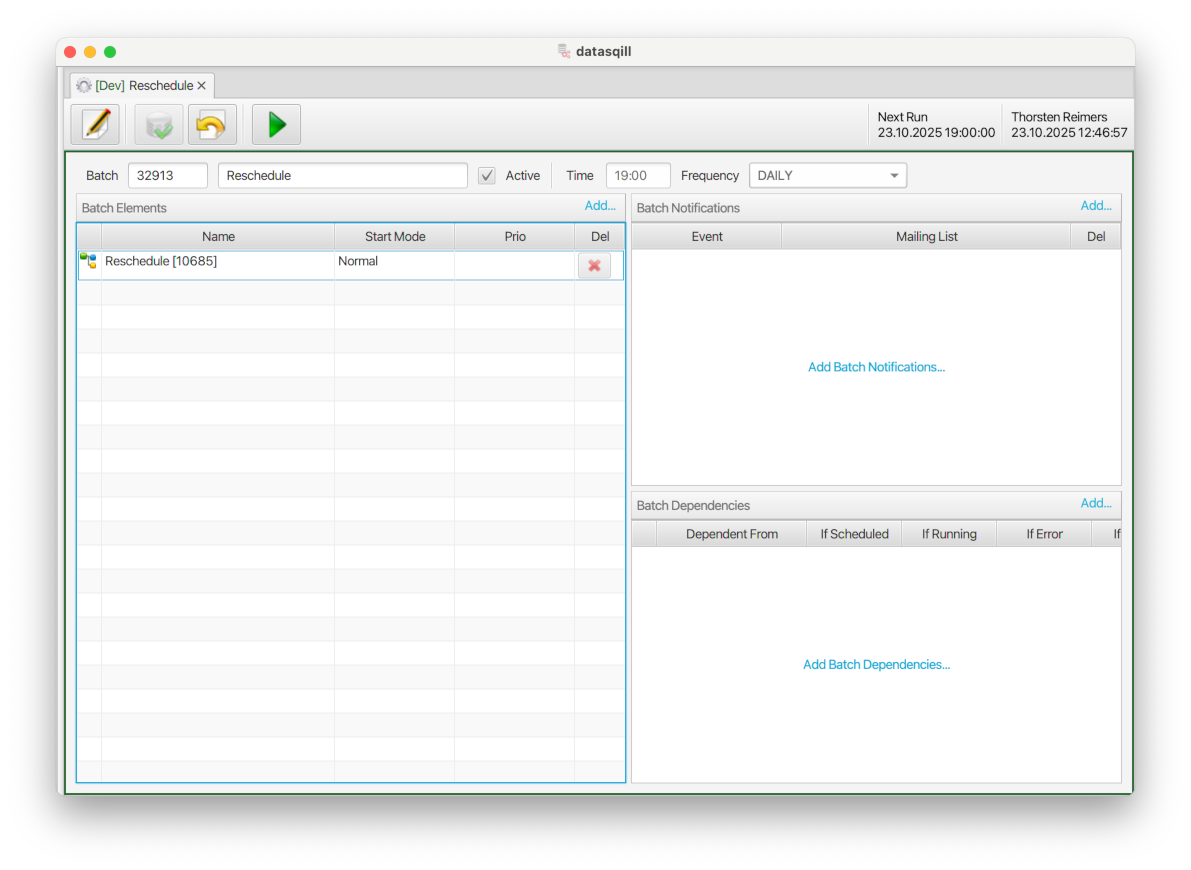
Abschließend wird ein neuer Batch "Reschedule" angelegt, der das Sheet täglich ausführt. Dabei sollte die Ausführungszeit vor allen anderen Batches liegen, die dieser Batch bei Zeitumstellung verschieben soll.
Im Beispiel läuft der Batch 6790 jede Nacht um 22:00 Uhr, der Reschedule Batch wurde deshalb für 19:00 Uhr geplant:
Jdbc Treiber verwalten
Zur Vereinfachung der Verwaltung der installierten Jdbc Treiber kann das Programm jdbcManager verwendet werden. Es liegt ab Version 4.1.4 im Verzeichnis "$HOME/bin" bei den übrigen datasqill Skripten.
Nach dem Start zeigt das Programm jdbcManager die installierten Jdbc Treiber. Mit ADD können neue Treiber hinzugefügt werden, mit DELETE vorhandene Treiber entfernt werden:
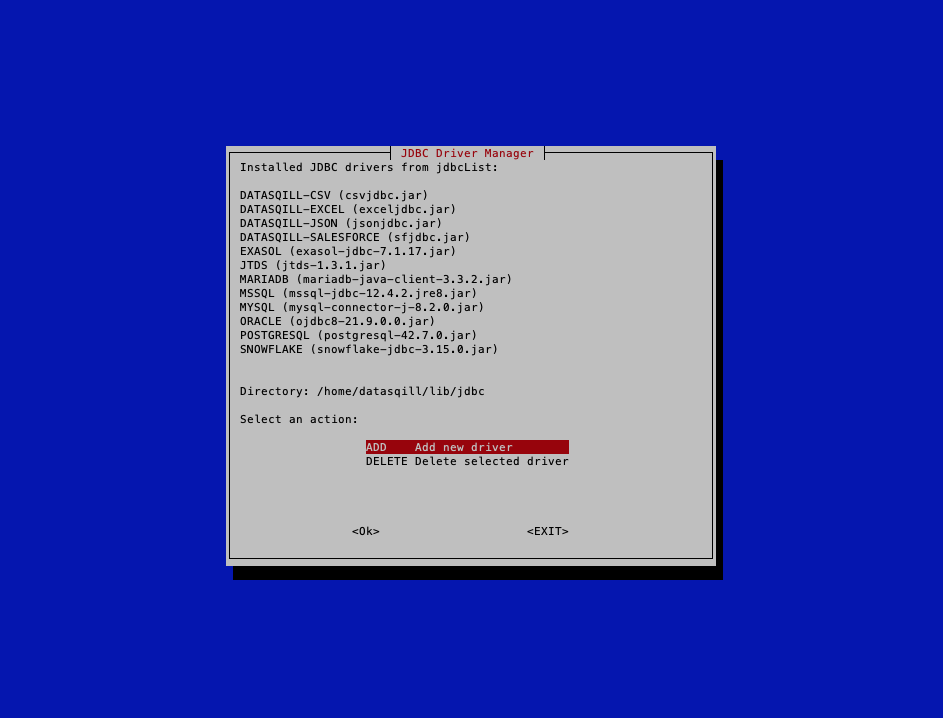
Beim ersten Start werden keine Jdbc Treiber angezeigt. Mit ADD können Treiber hinzugefügt werden.
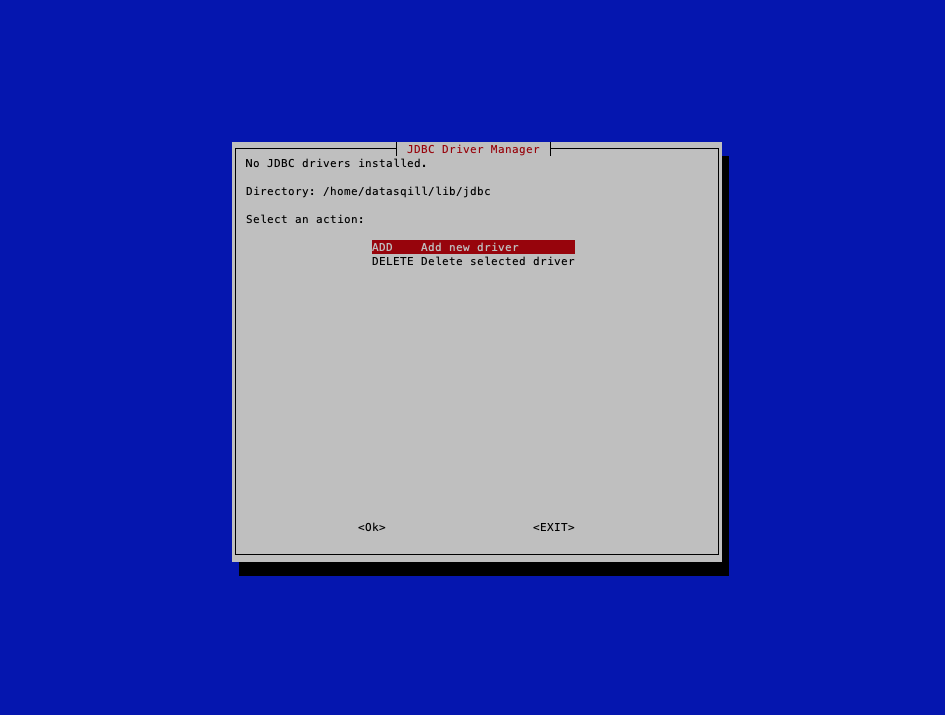
Dann erscheint eine Auswahl von Jdbc Treibern, von denen man einen zum Download und zur Installation auswählen kann.
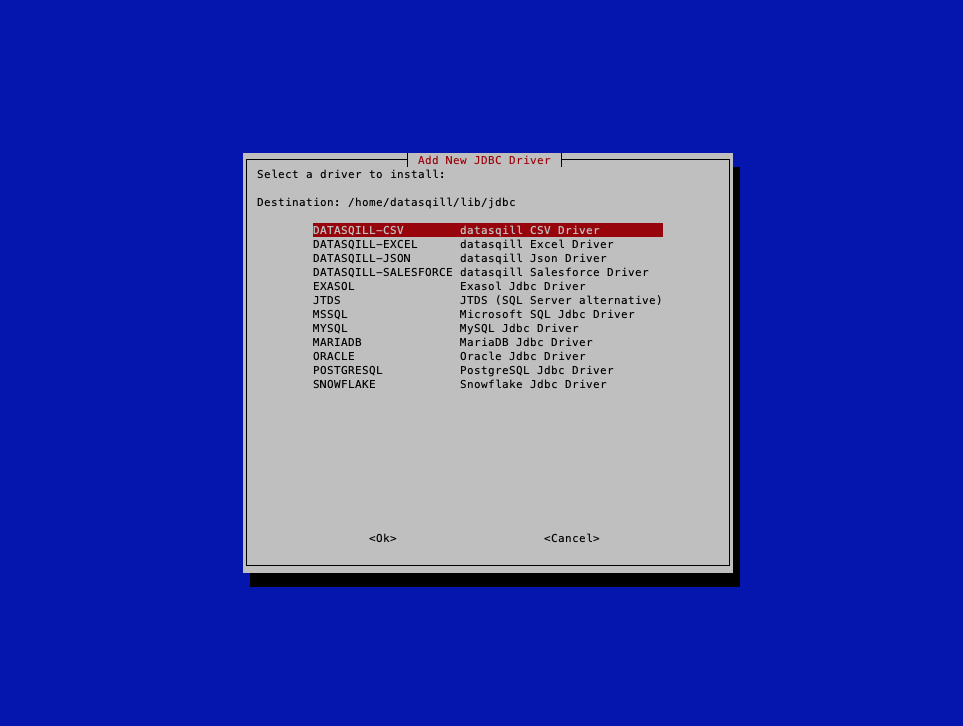
Es erscheint ein Fortschrittsbalken und nach Abschluss des Downloads ein Bestätigungsdialog.

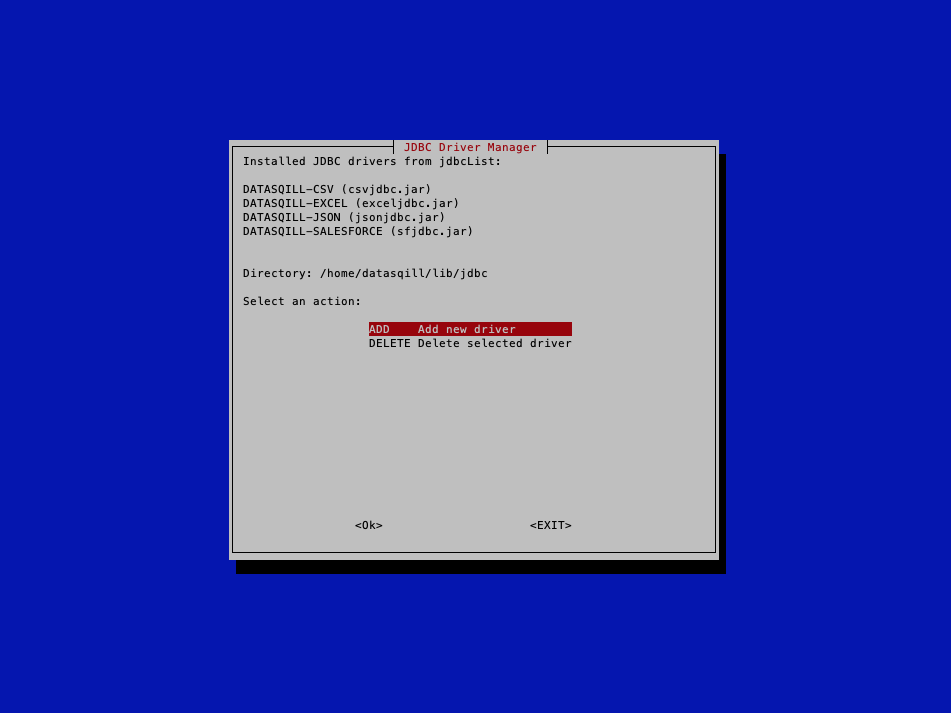
Danach ist der Treiber in datasqill installiert und erscheint in der Liste im Hauptmenü.
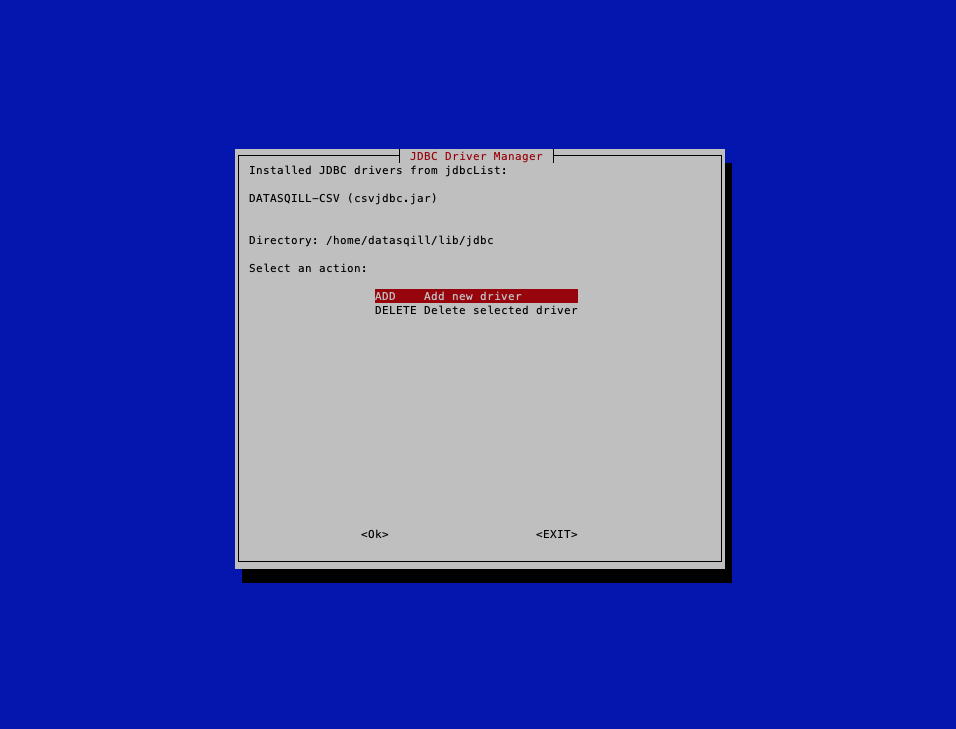
So kann man sukzessive weitere Treiber installieren.
Die verfügbaren Treiber und ihre Download-Urls werden über die Konfigurationsdatei "jdbcList" verwaltet, die im selben Verzeichnis wie das Skript selbst liegt. Sie sieht prinzipiell so aus:
# JDBC Driver Configuration
# Format: <name>:<description>:<maven-repo-url>
# datasqill CSV JDBC Driver
DATASQILL-CSV:datasqill CSV Driver:https://download.softquadrat.de/master/jdbc/csvjdbc.jar
# datasqill Excel JDBC Driver
DATASQILL-EXCEL:datasqill Excel Driver:https://download.softquadrat.de/master/jdbc/exceljdbc.jar
# datasqill Json JDBC Driver
DATASQILL-JSON:datasqill Json Driver:https://download.softquadrat.de/master/jdbc/jsonjdbc.jar
# datasqill Salesforce JDBC Driver
DATASQILL-SALESFORCE:datasqill Salesforce Driver:https://download.softquadrat.de/master/jdbc/sfjdbc.jar
...
Bei Bedarf können einfach weitere Treiber mit ihrem Namen und der Download-Url hinzugefügt werden.
Zulässige Urls beginnen mit "http:", "https:" oder "file:". Letzteres Format erlaubt die Installation von Dateien, die bereits auf dem Server liegen, zum Beispiel in einem gemounteten Fileshare.
# my jdbc driver
MY-DRIVER:My Jdbc Driver:file:///home/myuser/mydriver.jar