Monitoring / Runs
Ausführung
Generell können Transformationen, Arbeitsblätter und Ordner ausgeführt werden. Ein Rechtsklick auf eine Transformation im Arbeitsblatt (als auch auf dem Arbeitsblatt und Ordner in dem Baum) öffnet das Kontextmenü mit dem Eintrag Run. Die Auswahl dieses Eintrages sendet einen Request zum Scheduler, um die gewählte Transformation (oder Transformationen die sich auf dem Arbeitsblatt oder in dem Ordner befinden) nächstmöglich auszuführen
Die Verwendung der Schaltfläche Run sendet einen Ausführungsrequest für alle auf dem Arbeitsblatt befindlichen Transformationen zum Scheduler.
Auflösung von Abhängigkeiten
Abhängigkeiten zwischen Transformationen werden vom datasqill Scheduler automatisch erkannt und bei der Ausführungsreihenfolge berücksichtigt. Wenn eine Transformation A eine Tabelle benutzt, die von der Transformation B beschrieben wird, dann wartet die Transformation A bis die Transformation B fertig ist. Dazu ist es notwendig, die entsprechenden Transformationen in einem gemeinsamen Ausführungsrequest zu bündeln. Das ist implizit möglich über die Platzierung in einem gemeinsamen Arbeitsblatt oder über die explizite Hinterlegung in einem gemeinsamen Batch.
Die Abhängigkeiten ergeben sich nicht aus der Gesamtmenge der modellierten Transformationen, sondern aus dem Inhalt des jeweiligen Batches. Wenn nur eine einzige Transformation gestartet wird, dann werden die Abhängigkeiten zu den Quelltabellen nicht berücksichtigt, da die Transformationen, die in diese Tabellen schreiben nicht Teil des Batches sind. Es werden somit nur Abhängigkeiten zwischen den auszuführenden Transformationen ermittelt und berücksichtigt.
Abhängigkeiten bestehen nur zwischen Transformationen, werden aber über die verwendeten Objekte ermittelt.
Bei der Ausführung werden die Abhängigkeiten innerhalb eines Arbeitsblatts und arbeitsblattübergreifend unterschiedlich behandelt:
Abhängigkeiten innerhalb eines Arbeitsblatts
Es existiert nur eine einzige Regel: Die Ablaufreihenfolge ergibt sich exakt aus den modellierten Verbindungen zwischen den Transformationen (blaue Kästchen).
Wenn die Transformation A ein Objekt (graues Kästchen) verwendet, welches von der Transformation B beschrieben wird, dann wird die Transformation B erst starten, nachdem Transformation A erfolgreich abgechlossen ist.
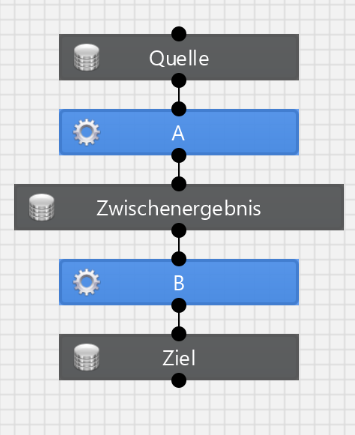
Die Einstellung der Abhängigkeiten im Objekt (Dependency Wait/Ignore) haben keine Bedeutung für die Abhängigkeit innerhalb eines Arbeitsblatts.
Abhängigkeiten in der Datenbank werden innerhalb eines Arbeitsblatts nicht herangezogen. Beispiel: Die Tabelle 1 wird in der Definition von der View 1 benutzt und folgende Transformationen sind modelliert:
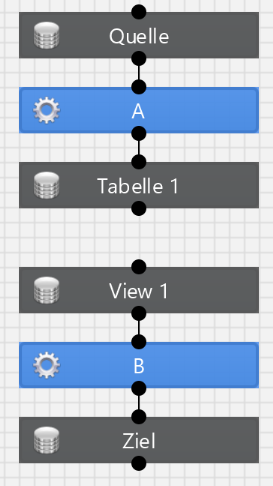
Dann würden die Transformationen A und B parallel laufen, obwohl es innerhalb der Datenbank eine Abhängigkeit gibt.
Möchte man diese Abhängigkeit berücksichtigen, muss man sie manuelle modellieren:
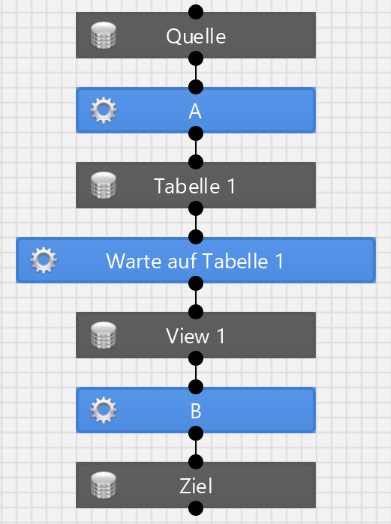
Hierbei ist die Transformation "Warte auf Tabelle 1" eine virtuelle Transformation (Type Virtual).
Objekte mit gleichem Namen
Innherhalb eines Arbeitsblattes ist es für die Ablaufreihenfolge unerheblich, ob es sich auf dem Arbeitsblatt das gleiche Datenbankobjekt (gleiche Datenbank, gleiches Schema und gleicher Name) mehrfach befindet. Aufgrund der Tatsache, dass sich das Object in unterschiedlichen Zuständen befindet sind es aus der Sicht des Ablaufes unterschiedliche Objekte. Hierzu ein Beispiel:
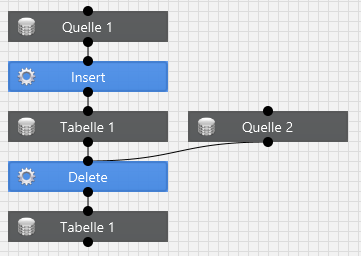
In diesem Beispiel wird erst eine Tabelle mit Daten gefüllt und danach werden einige Zeilen wieder herausgelöscht. Die Objekte mit dem Namen "Tabelle 1" sind zwar in der Datenbank identisch, müssen aber aus der Sicht des Ablaufs unterschiedlich behandelt werden. In diesem Beispiel ist eine Abhängigkeit modelliert.
Folgendes Beispiel verwendet auch wieder zweimal die gleiche Tabelle, jedoch existieren hier keine Abhängigkeiten:
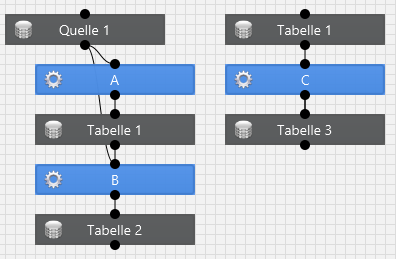
In diesem Beispiel ist nicht sichergestellt auf welchen Zustand die Transformation C Tabelle 1 vorfindet. Transformation A kann aber muss nicht schon gelaufen sein, oder ist zeitgleich mit Transformation C aktiv. Dieses Konstrukt verwendet man, wenn die Transformationen A und C auf unterschiedlichen Telmengen der Tabelle 1 operieren. Ein Besipiel wäre, wann Tabelle 1 eine Steuertabelle ist, die pro Transformationslogik einen gesonderten Eintrag hat.
Alle diese vorstehenden Erklärungen unterstreichen die einfache Regel: Die Ablaufreihenfolge ergibt sich exakt aus den modellierten Verbindungen zwischen den Transformationen.
Arbeitsblattübergreifende Abhängigkeiten
Arbeitsblattübergreifende Abhängigkeiten werden ausschließlich über den Namen ermittelt. Hierbei werden aktuell nur Datenbankobjete berücksichtigt. Beim Vergleich müssen Datenbank (Connection) Schemaname (Schema) und Tabellenanme (Table) übereinstimmen.
Regel 1: Bei einem modellierten Objekt, in dem die Option Dependency auf "Ignore" gesetzt ist, werden für alle Transformation, die dieses Objekt verwenden, keine Anhängigkeiten aus anderen Arbeitsblättern mit gleichem Namen herangezogen.
Regel 2: Bei einem modellierten Objekt, in das im Modell von einer Transformation geschrieben wird (als Ziel verwendet), werden bei Transformationen, die diese Objekt verwenden, keine weiteren Anhängigkeiten mit gleichem Namen aus anderen Arbeitsblättern herangezogen.
Regel 3: Bei allen anderen modellierten Objekten, werden bei Transformationen, die diese Objekt verwenden, Anhängigkeiten mit gleichem Namen aus anderen Arbeitsblättern herangezogen.
Beispiel für Regel 2:
Arbeitsblatt 1

Arbeitsblatt 2

In diesem Beispiel wartet die Transformation B nicht auf Transformation C.
Schleifen
Benötigt Transformation A direkt oder indirekt Transformation B und Transformation B benötigt direkt oder indirekt Transformation A, dann kommt es zu einer Verblockung. Somit ist in den Abhängigkeiten eine Schleife entstanden. Dieses führt dazu, dass der Ablauf alle Transformationen erledigt, die nicht innerhalb dieser Schleife sind und nicht auf Transformationen innerhalb dieser Schleife warten. Danach steht die Gesamtausführung immer nach auf "Aktive" aber alle Transformationsausführungen sind im Status "Dependency Wait".
Die Auflösung dieser Schleifen muss manuelle erfolgen. Diese erreicht man dadurch, dass man die Transformation, die man nun als erstes ausführen möchte manuelle in einem neuen Batch ausführt und sie danach in diesem Ablauf mit "Skip Task" überspringt.
Ordner administrieren
Der Dialog zum Anlegen eines neuen Ordners wird über den Eintrag New Folder im Kontextmenü des Explorers geöffnet. Im Dialog wird der Name des Ordners eingegeben und der Ordner mit OK erzeugt. Ein Ordner kann über den Eintrag Delete in seinem eigenen Kontextmenü gelöscht werden.
Arbeitsblätter administrieren
Der Dialog zum Anlegen eines neuen Arbeitsblattes wird über den Eintrag New Sheet im Kontextmenü des Explorers geöffnet. Im Dialog wird der Name des Arbeitsblattes eingegeben und das Blatt mit OK erzeugt. Ein Arbeitsblatt kann über den Eintrag Delete in seinem eigenen Kontextmenü gelöscht werden.
Monitoring / Runs
Der Bereich Runs im Explorer enthält die Statusinformationen der vom Scheduler gesteuerten Transformationsläufe. Er teilt sich in die beiden Bereiche Recent und Finished.
- Der Ordner Finished enthält Datumsordner, die wiederum die an diesem Tag stattgefunden Batches enthalten, die sich in einem finalen Status befinden.
- Der Ordner Recent enthält Läufe die sich noch nicht in einem finalen Status befinden und Läufe in einem finalen Status, die am aktuellen Tag stattgefunden haben.
Ein Doppelklick auf einen Lauf im Explorer öffnet die Batch Transformationen Ansicht dieses Laufes im Editorbereich.

Batch Transformationen
Die Batch Transformationen Ansicht enthält die Informationen zu allen in einem Batch enthaltenen Transformationen in Listenform. Zu den angezeigten Informationen gehören u.a. Name des Arbeitsblattes, Name der Transformation, Status der Transformation, Startzeitpunkt, Endzeitpunkt, Dauer, Error Code, Anzahl verarbeiteter Zeilen, u.a. mehr. In der Batch Transformationen Ansicht stehen über die Schaltflächenleiste folgende Funktionalitäten zur Verfügung:
- Resume Batch: setzt einen angehaltenen Batch fort
- Halt Batch: hält einen laufenden Batch an. Die Transformationen, die noch laufen, laufen bis zum Ende, es werden aber keine weiteren gestartet.
- Abort Batch: beendet einen angehaltenen Batch final. Die Transformationen, die zum Zeitpunkt des Abbruchs noch laufen, laufen bis zum Ende. Alle weiteren Transformationen werden auf „beendet“ gesetzt.
- Show History: bei gesetzter Show History werden auch frühere (unerfolgreiche) Laufversuche von Transformationen des Batches angezeigt
- Refresh Cycle: enthält die Einträge zur Auffrischungsfrequenz der Ansicht mit den möglichen Werten Manually, 5 sec, 15 sec, 60 sec
- Refresh: Schaltfläche zur manuellen Auffrischung der Ansicht
Einzelne Elemente des Batches können über die Einträge im Kontextmenü der jeweiligen Zeile erneut gestartet (Restart Task) oder übersprungen (Skip Task) werden. Ein Doppelklick auf den Namen der Transformation in der Ausführungsliste öffnet die Ansicht der Transformationsausführung.
Ansicht der Transformationsausführung
Die Ansicht der Transformationsausführung stellt die Informationen über eine Transformationsausführung als Schlüssel-/Wertpaar dar. Die Transformationsausführung kann über die Schaltfläche Restart Task wieder angestartet und über Skip Task übersprungen werden. Der Eintrag „Restart Task“ startet die Transformation neu in dem zu dem Batch-Startzeitpunkt gültigen Zustand. Änderungen an der Transformation werden also nicht berücksichtigt. Wenn die Transformation korrigiert wird, dann muss sie einzeln gestartet werden, nicht als Bestandsteil des Batches.
Temp Space Überwachung
Durch den Scheduler findet eine dauerhafte Überwachung des verwendeten Temp Space statt, um eine häufige Fehlerursache bei Läufen zu vermeiden. Hierzu werden im Hintergrund aktuelle und historische Daten der Läufe ausgewertet, um zu entscheiden, ob eine Aktion mit dem noch zur Verfügung stehenden Temp Space (Systemparameter) möglichst erfolgreich gestartet werden kann.